

I also wrote a Chinese edition of this article, and it can be found here.
As we know, Nvidia’s CUDA computing platform features impressive massively parallel computing, and underpins almost all modern popular machine learning frameworks. To get my hands dirty on artificial intelligence, I recently built a computer with a budget GeForce GTX 1060 graphics card.
This Zotac-manufactured graphics card has 1280 CUDA cores and 6 GB GDDR5 memory.

I carried out two simple tests and write the results here for further reference. The first test ran a CUDA C++ program that calculates two arrays, each has 1 million float numbers, and gave a speedup of more than 2000 times. The second test trained a Keras + TensorFlow model for recognizing the MNIST handwritten digits, and delivered a 10 times speedup.
Adding Two Large Float Arrays
According to the great CUDA introduction article, An Even Easier Introduction to CUDA, written by Mark Harris on Nvidia Developer Blog, I wrote a simple program to calculate element-wise addition of two arrays, each has 1 million float numbers.
CUDA’s parallel computing style is called SIMT, standing for single instruction, multiple threads. In CUDA jargon, a function executed by GPU is called a kernel. To make computing parallel, CUDA dispatches threads into a thread grid, which consists of numBlocks blocks, each block consists of blockSize threads. To call a CUDA function (kernel), the two parameters, numBlocks and blockSize, must be specified within a pair of triple angle brackets right after the function name.
add<<<numBlocks, blockSize>>>(N, x, y);Where N is the length of arrays, x is the first array, and y is the second array.
Using nvprof to profile the program with different numBlocks and blockSize, I got the results as below.
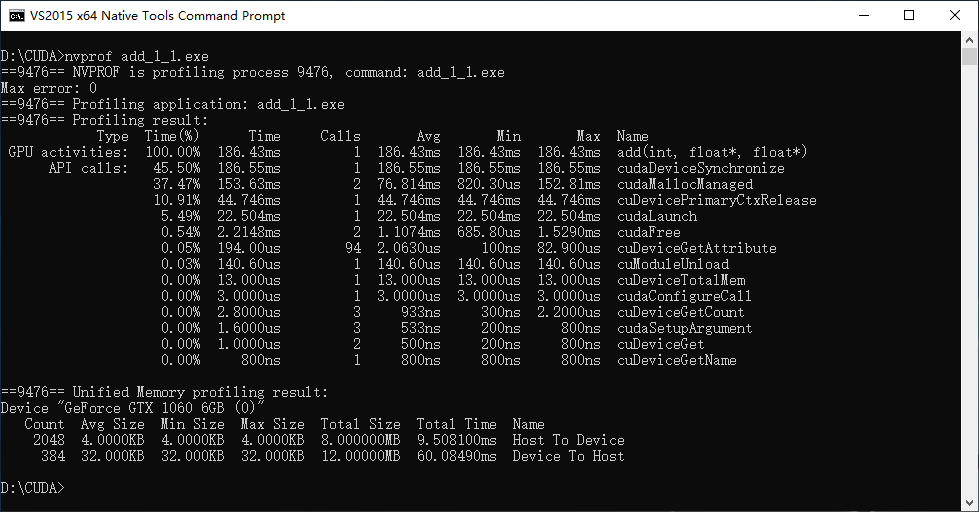
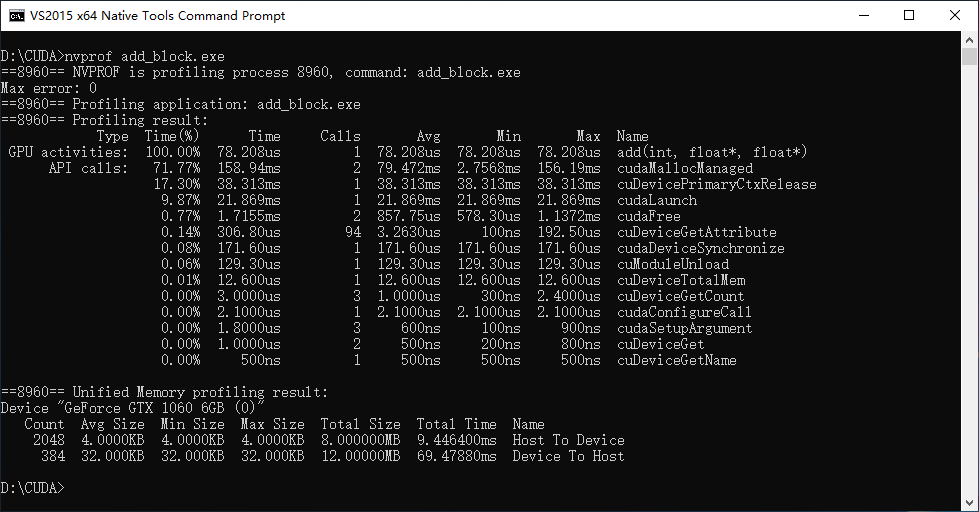

The numBlocks (3907) on the last row is calculated before calling the add function.
numBlocks = (N + blockSize - 1) / blockSize;From the profiling results above, the conclusion can be drawn that a huge speedup of 2383 times was obtained by taking full use of CUDA’s SIMT parallel computing resource.
Training MNIST Model
The second test is to train a simple deep network for recognizing the well-known MNIST handwritten digital database. The code is modified from a great article by Vikas Gupta, Image Classification using Feedforward Neural Network in Keras.
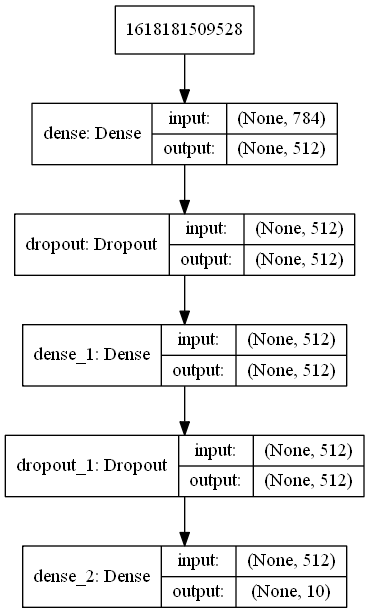
Keras offers a series of high-level APIs, with backends such as TensorFlow and other machine learning frameworks. To compare the boost results, I performed the training on two backends, namely TensorFlow-CPU and TensorFlow-GPU, respectively, on the same machine.
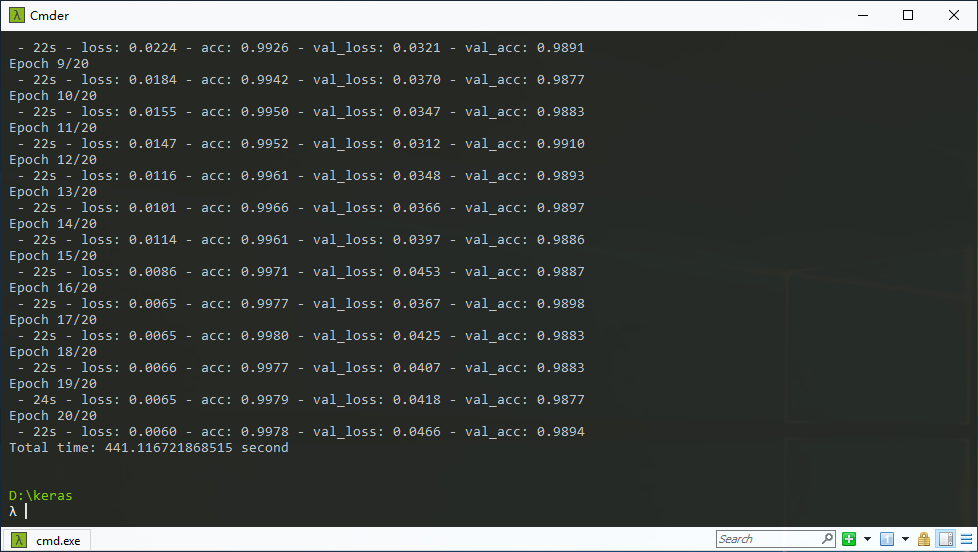

As shown in Figure 8, in the pretty simple deep network test, a 10 times speedup can be achieved via GPU.
Conclusion
Now we can draw the conclusion. In some applications that its calculation can be paralleled, even a previous generation budget gaming graphics card can deliver significant performance boost, thanks to its vast number of CUDA cores (1280 cores in my graphics card).
As I come from a non-tech industry, and all these coding and GPU knowledge is taught by myself, so if you find anything wrong in this article, please just kindly tell me.